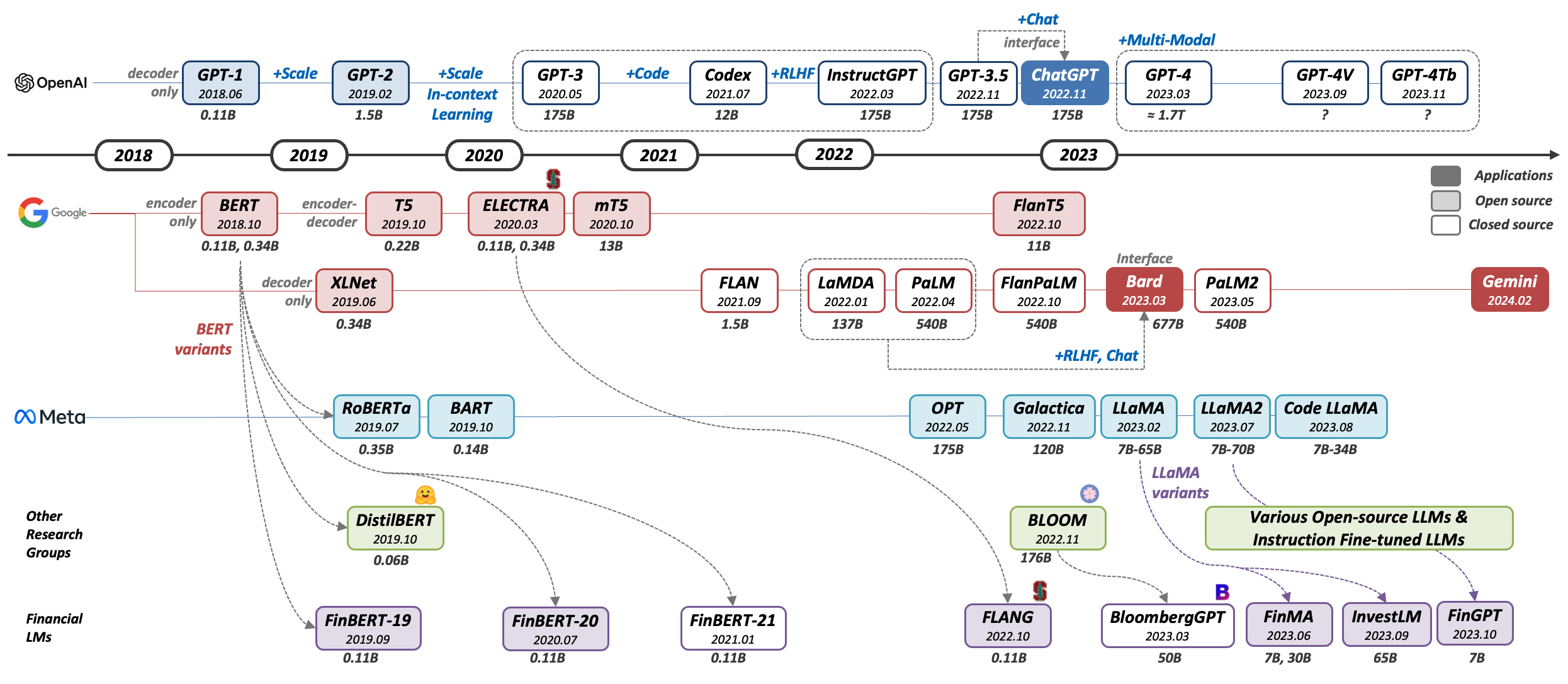
Large Language Models in Finance (FinLLMs).
Accepted by NCAA (Q1) 2025.

Dr Jean Lee is an Associate Lecturer at the School of Computing and Information Systems (CIS) at the University of Melbourne. She holds a PhD in Computer Science (NLP) and a Master of Data Science from the University of Sydney, supervised by Dr Caren Han and A/Prof Josiah Poon. Her current research focuses on AI in Education, Large Language Models, Multimodal Learning, and AI applications. Jean's research has been published in top-tier AI/NLP conferences (e.g. ACL, AAAI, SIGIR, NCAA, COLING), and she has participated in Google Research and NVIDIA workshops as a tutor/mentor. She also reviews for several international AI conferences and journals (e.g. IJCAI, AJCAI, ICPR, EMNLP, IEEE TCSS, Journal of Empirical Finance, Journal of Behavioral Finance). Based on her successful research progress during her PhD, she was awarded a Research Training Program (RTP) Scholarship by the Australian Government. Prior to academia, Jean passed the U.S Uniform Certified Public Accountancy Examination (a.k.a. AICPA), received an MBA from Seoul National University, and worked in management consulting firms, including Accenture and KPMG.
order by date descending
Accepted by NCAA (Q1) 2025.
...Despite the extensive research into general-domain LLMs, and their immense potential in finance, Financial LLM (FinLLM) research remains limited. This survey provides a comprehensive overview of FinLLMs, including their history, techniques, performance, and opportunities and challenges...

Publications by Springer 2025.
...This book provides a comprehensive introduction to conversational spoken language understanding and surveys recent advances in conversational AI. It guides the reader through the history, current advancements, and future of natural language understanding (NLU), including a presentation of real-world applications in finance, medicine, and law.
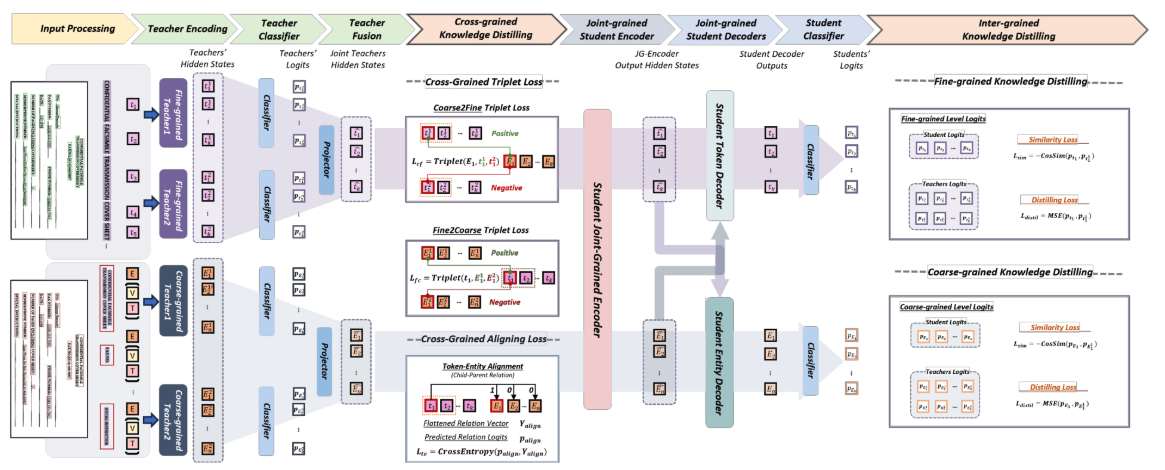
Accepted by ACL 2024.
...designed to leverage insights from both fine-grained and coarse-grained levels by facilitating a nuanced correlation between token and entity representations, addressing the complexities inherent in form documents. Additionally, we introduce new inter-grained and cross-grained loss functions to further refine...
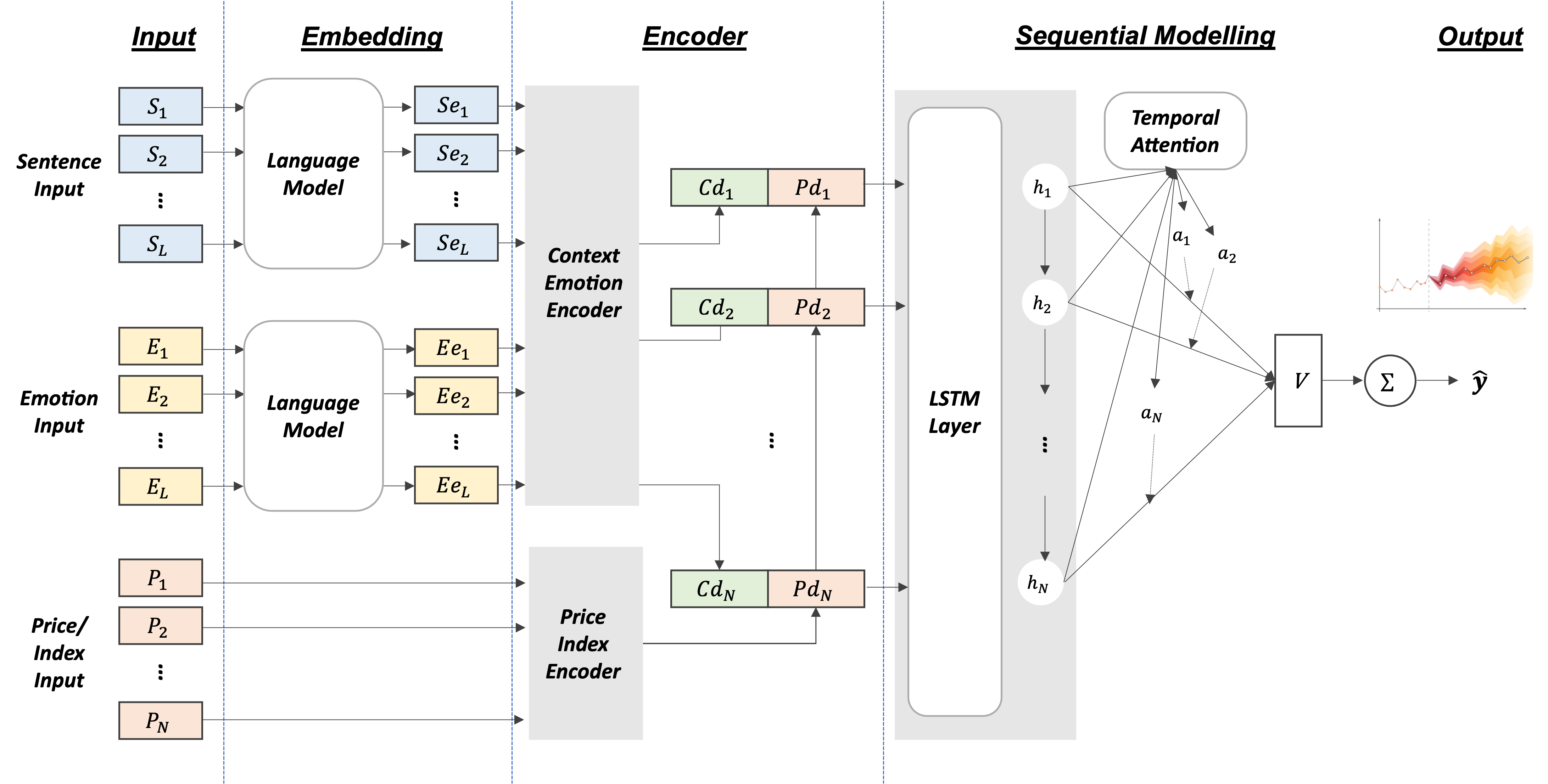
Accepted by AAAI 2023 Bridge.
Paper | Github | PaperWithCode
...a new dataset for detecting emotions in the stock market that consists of 10k English comments collected from StockTwits. Inspired by behavioral finance, it proposes 12 fine-grained emotion classes that span the roller coaster of investor emotion. Unlike existing financial sentiment datasets, StockEmotions presents granular features such as investor sentiment classes, fine-grained emotions, emojis, and time series data....

Accepted by COLING 2022.
Paper | Presentation | Github
Online Hate speech detection has become important with the growth of digital devices, but resources in languages other than English are extremely limited. We introduce K-MHaS, a new multi-label dataset for hate speech detection that effectively handles Korean language patterns. The dataset consists of 109k utterances from news comments and provides multi-label classification...

Accepted by ACL-IJCNLP 2021.
Paper | Presentation | Github
Traditional toxicity detection models have focused on the single utterance level without deeper understanding of context. We introduce CONDA, a new dataset for in-game toxic language detection enabling joint intent classification and slot filling analysis, which is the core task of Natural Language Understanding. We propose a robust dual semantic-level toxicity framework...
Accepted by SIGIR 2021.
Paper | Presentation | Demo | Github
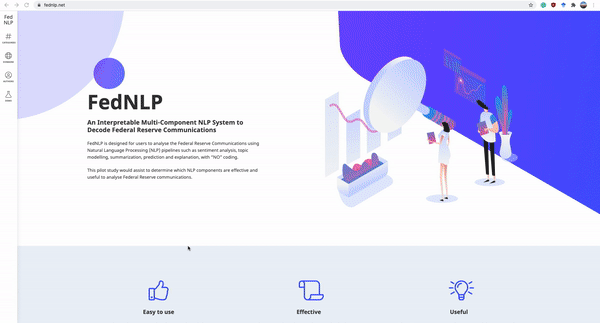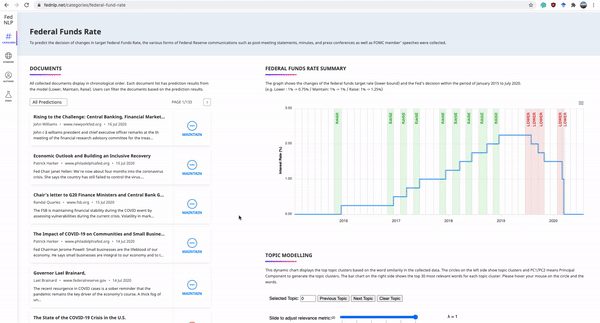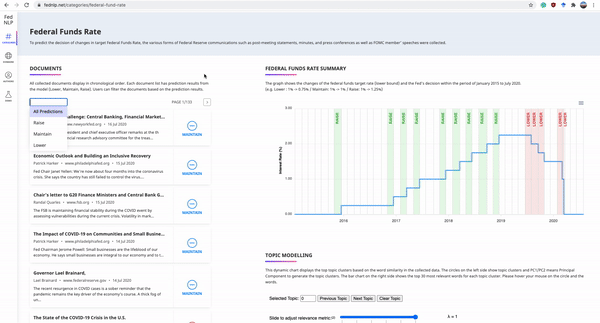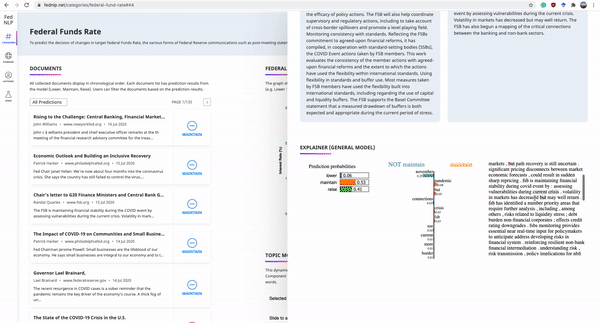
The Federal Reserve System plays a significant role in affecting monetary policy and financial conditions worldwide. ...we present FedNLP, an interpretable multi-component Natural Language Processing system to decode Federal Reserve communications. This system is designed for end-users to explore how NLP techniques can assist their holistic understanding of the Fed's communications with NO coding...
I have been teaching Python programming, Data Science, Machine Learning, and Deep Learning for Natural Language Processing at the University of Melbourne and the University of Sydney for five years: Award recipient of the FEIT Excellence Award in Education (Tutor, 2025) and the FEIT Community Award (Tutor of the Year, 2025) at the University of Melbourne, and the Outstanding Achievement in Teaching - Feedback for Teaching (FFT) Student Survey (2023 - 2024) at the University of Sydney.
Leveraging with my working experience and data science skills, my goal is to pursue my research career in AI specialising in NLP. A brief summary of my career is below:
| Company | Position, Department | Period |
|---|---|---|
| Univ. of Melbourne | Associate Lecturer | Computing & IS | Jan. 2025 - Present |
| Univ. of Sydney | Researcher & Data Scientist | Sydney Informatics Hub | Aug. 2024 - Jan. 2025 |
| Univ. of Sydney | Casual Academic | Computer Science, Business | Jan. 2021 - Jan. 2025 |
| Accenture | Management Consultant | Strategy | Mar. 2012 - Feb. 2014 |
| KPMG | Management Consultant | Climate Change & Sustainability | Jul. 2011 - Sep. 2011 |